")
")
")
")
")
")
")
")
")
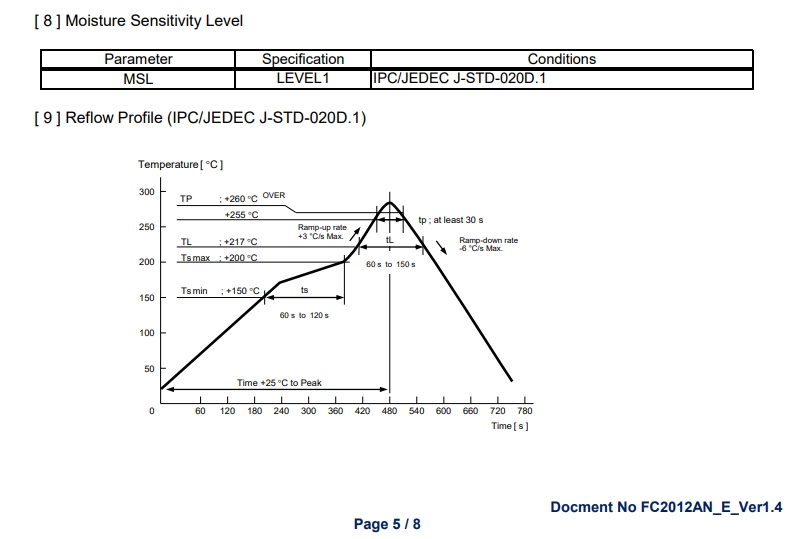
")
")
")
")
")
")
")













“跑一个70B年夜模子,先患上预备800万元买显卡?”——这不是段子,是大都企业AI当地化立项书的第一行数字。
人工智能正之前所未有的深度与广度重塑千行百业,然而当企业投身在AI当地化部署时,两年夜底子性瓶颈绵亘面前:一是数据“供不上、存不下”的困局;二是于动辄数百GB的AI模子眼前,GPU“寸土寸金”的显存墙。
当“显存墙”越砌越高,财产界的梯子却分出两条大相径庭的搭法。一条是“算力派”的直梯——把高端GPU像积木同样继承往上码,用更多的H100、A800去换“寸土寸金”的显存空间;另外一条是“体系派”的折叠梯——于存算之间插入一层“弹性夹层”,把冷数据、温数据、热数据按温度梯度逐层腾挪,用软件界说及异构硬件去挤出分外的容量与带宽。
外洋已经有微软DeepSpeed、AMD Infinity Cache探路,国产阵营里,铨兴科技把这套“夹层”思绪拆成两半:先用122 TB QLC eSSD等产物搭起“高机能eSSD矩阵”,把PB级模子权重稳稳落于闪存里;再用“添翼当地AI超显存交融方案”把FPGA节制器引入PCIe通道,于微秒级完成数据搬运,仅把当前最活跃的激活张量留于GPU显存——单机便可开释20倍等效显存空间,成本锐减90%,无需分外购置旗舰卡。
铨兴科技全场景eSSD矩阵锻造AI的坚实数据底座AI事情流的效率,素质上是数据流动的效率。从数据预备、模子练习到推理运用,每一个环节对于存储的要求都大相径庭。单一的存储方案没法实现最优的成本效益。铨兴科技的计谋是提供一套条理清楚、精准匹配运用场景的eSSD产物矩阵,确保每一一分投入都用于刀刃上。
01QLC 122TB单盘,拓宽推理堆栈的容量界限
当AI模子进入推理(Inference)与检索加强天生(RAG)的运用阶段时,存储的焦点抵牾便从“混淆读写”转向了“读取密集型”负载。

铨兴科技的高密度QLC eSSD系列,恰是应答这一场景的“容量巨兽”及成本效益优化器。它基在PCIe5.0接口,具有14,000MB/s的顶级挨次读取速率及跨越300万的随机读取IOPS,确保了AI运用于面临海量并发哀求时,依然能提供低延迟的瞬时相应。
其最为显著的上风,于在将单盘容量前所未有地推升至122.88TB。这象征着,客户可以用远少在传统方案的硬盘数目、办事器以致机柜空间,去构建PB级另外AI数据湖及模子常识库。这不仅年夜幅简化了数据中央的物理部署,更于电力耗损、冷却及运维上带来了显著的成本勤俭,从底子上优化了AI运用持久运行的整体拥有成本(TCO)。
02从PCIe 5.0到SATA,给练习盘留一条带宽阶梯
相较在AI推理阶段的读取密集型负载,更前真个模子练习、年夜范围数据处置惩罚以和高机能计较(HPC)等企业级营业,则对于存储体系提出了更为繁杂及严苛的“混淆读写”磨练。这种场景不仅需要极致的读取速率来防止GPU等焦点算力单位的空转,更需要强悍且不变的写入能力来应答频仍的数据更新与查抄点操作。
为应答这一挑战,铨兴科技的TLC产物矩阵提供了条理清楚的解决方案。其旗舰级的PCIe 5.0 TLC eSSD系列,恰是为上述对于速率要求最为苛刻的场景而设计。它依托PCIe 5.0的超高带宽,提供了高达14,000 MB/s的挨次读取速率与3300K的随机IOPS,确保于数据抽取与加载环节,能以最快速率“喂饱”算力焦点。

同时,其强劲的写入机能,能将AI练习中生存查抄点所需的时间视窗压缩到最短,从而显著晋升有用练习时长。更主要的是,该系列产物具有高达3 DWPD的企业级写入经久度及立异的Dual Port(双端口)设计,为动辄耗时数月、7x24小时不间断运行的AI练习使命,提供了企业级的靠得住性与高可用性保障。
并不是所有企业级运用都需要PCIe 5.0的极致吞吐能力,广泛的平台兼容性及部署矫捷性一样至关主要。为此,铨兴科技TLC产物矩阵中还有包罗了高耐用性的2.5英寸SATA TLC eSSD系列。
该系列产物专注在于各种主流办事器平台中提供不变靠得住的存储撑持,其容量可扩大至15.36TB,并可按照客户详细的运用负载,提供从0.5到3不等的DWPD经久度等级。这类高度客制化的能力,使其能矫捷适配从温、冷数据存储到要求更严苛的企业运用等多样化的部署场景。
依附这一统筹机能与兼容性的产物结构,铨兴科技的企业级存储解决方案,已经于AI办事器、数据中央、高机能计较、云存储、数据库等多个焦点场景获得运用。其产物已经经由过程了包括高潮、龙芯、海光、兆芯以和中泰证券、北京邮电年夜学于内的多家国产化平台及行业客户的严酷验证,证实了其于多场景下的靠得住性与兼容性。
从168张到16张卡超显存方案怎样铺平账单?AI年夜模子的当地化部署,正面对一个焦点悖论:模子参数的指数级增加与GPU显存的线性增加之间,形成为了巨年夜的鸿沟。以一个671B参数的年夜模子为例,传统硬件配置需要一个由168张顶级显卡组成的重大集群,成本高达4200万元。这一由巨额成本砌成的“显存墙”,正将无数巴望拥抱AI厘革的高校、科研机构与中小企业拒之门外。
从财产趋向来看,“显存扩大技能”已经成为降低AI硬件成本的主要标的目的,行业内已经有经由过程软件虚拟化、内存扩大等方式晋升显存使用率的测验考试,但遍及存于机能损耗或者兼容性问题。铨兴科技推出的全离线、软硬一体“添翼AI”超显存交融解决方案,以“超维显存交融技能”为焦点,试图经由过程软硬协同的分层存储架构,于不转变现有GPU配置的条件下,实现等效显存容量的倍数级扩大,让年夜模子普惠化成为可能。

该方案的焦点于在其自研硬件与焦点算法的深度交融。其硬件基础是一块专为AI负载设计的“添翼AI扩容卡”,它于体系中饰演着GPU高速缓存扩大的脚色;而付与这块硬件“聪明”的,则是作为智能调理中枢的“AI Link算法平台”,它卖力于GPU原生显存与扩容卡之间举行微秒级的无感数据互换。
这类软硬一体的架构重构,为AI项目的硬件成本带来了数目级的优化。其要害于在,“添翼AI扩容卡”将单卡的等效显存容量有用扩大了20倍。这一冲破使患上算力部署再也不依靠在天价的显卡重叠,原先需要168张顶级显卡的重大练习使命,如今仅需一个由16张中阶显卡组成的紧凑型事情站便可胜任。
不仅云云,巨年夜的成本勤俭并未以捐躯机能为价钱。患上益在“AI Link算法平台”的智能调理,模子推理的并发机能还有能得到高达50%的晋升,实现了成本与效率的两重冲破。
为了让这一强盛的技能组合能被轻松驾御,并转化为真正的出产力,铨兴科技进一步提供了“AI Studio”软件平台,作为毗连强盛底层能力与用户的桥梁。该平台提供了一个低代码的图形化界面,将繁杂的模子练习、部署、量化等流程年夜幅简化,旨于极年夜降低用户的操作门坎,让更多范畴的专家可以或许便捷地使用AI技能。
为了让这一立异技能能快速转化为出产力,铨兴科技进一步推出了笼罩全场景的“Super AI”训推一体机系列,为差别用户提供开箱即用的解决方案:
Super AI PC (训推一体机): 针对于草创团队及小型开发组,提供从“练习到推理”的完备闭环,其内置的AI Cache能有用加快练习效率,是小团队AI开发的“万能东西箱”。
Super AI事情站 (训推一体机): 专为专业级模子开发设计,经由过程多GPU与加快模块的组合,有用解决“模子迭代慢、数据不安全”的焦点痛点,是保障长周期开发效率的“出产力站”。
Super AI办事器 (训推一体体): 面向企业级年夜模子落地,以多卡集群与AI加快能力,将“千亿模子训推”从耗时数月压缩至可控周期,是保障超年夜型模子乐成落地的“攻坚平台”。
依附领先的技能方案与显著的成本上风,铨兴科技的“添翼AI”解决方案已经经率先于政务、法令、高校等垂直行业实现了乐成落地。同时,公司正与遐想等体系集成商(SI)伙伴深度互助,以更成熟易用的产物形态,满意差别行业的多样化需求,配合加快AI普惠化的进程。
结 语人工智能走向财产纵深,终于要回到基础举措措施的厚度。铨兴科技于“存力”与“智算”两条技能栈并行结构,先用百TB级QLC把每一GB存储价格压到新低,再用缓存加快卡把显存压力部门卸载到闪存,两者叠加,为单机运行百亿级年夜模子提供了新的性价比路径。跟着政务、高校等场景陆续落地,这一方案为行业提供了可不雅测的参考路径:于GPU价格仍处高位确当下,经由过程QLC与分层缓存换取等效显存,有望让AI普惠化再下沉一个台阶。
-彩神vll(中国)

